Qualifying
Where do LLMs live in our professional practices, norms, and relationships?
The first block is about adopting a reflexive posture towards the use of LLMs. Participants engage in exercises that help them become more aware of their practices, attitudes, and assumptions about AI technologies.
This block serves as a foundational phase, akin to a practice ground, where participants start to think critically about their relationship with LLMs.

Exercise 1 - Draw It Like You See It
Participants sketch how they think an LLM works and how they view their work environment.
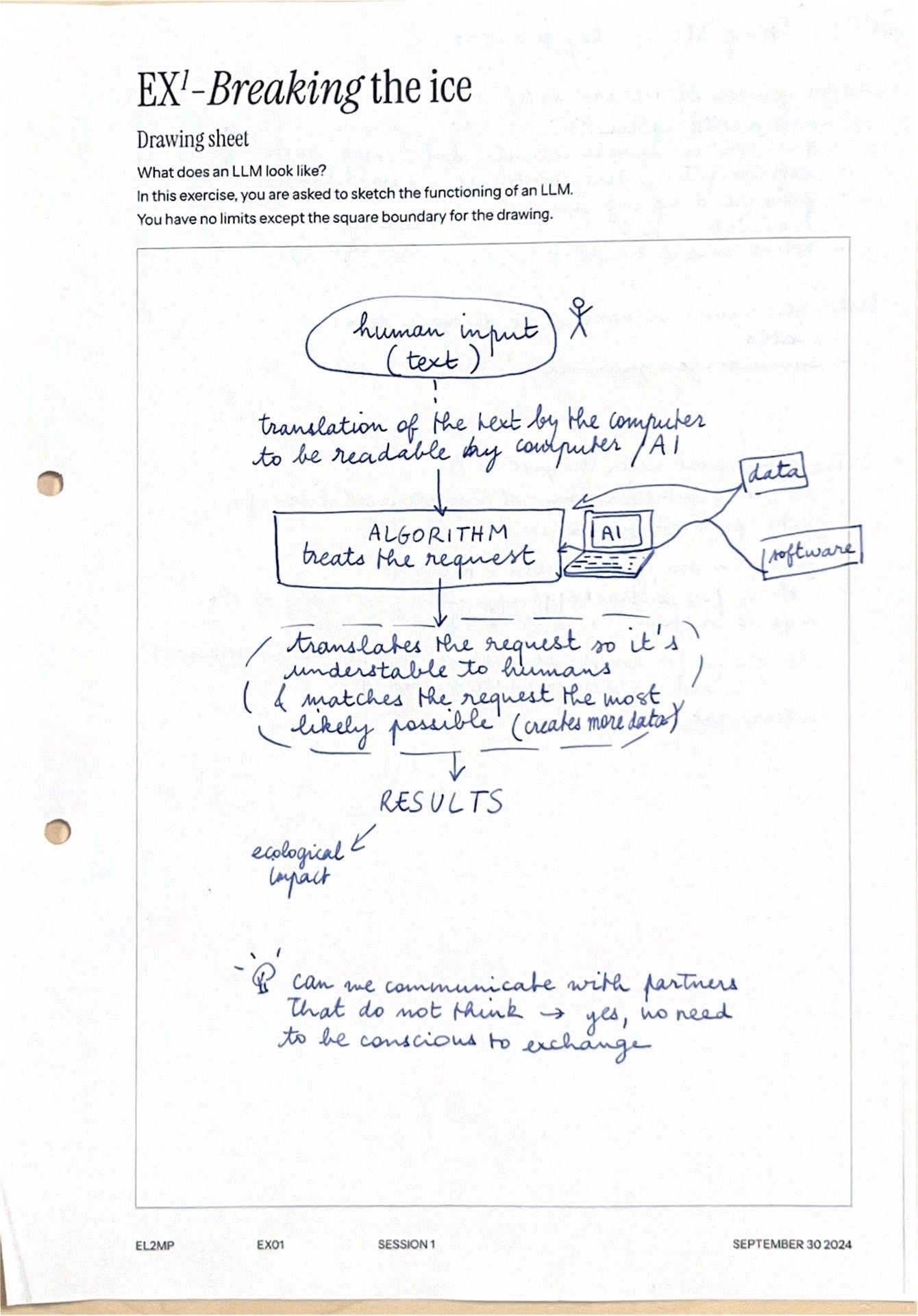
This exercise introduces participants to one another and to the project's exploration of the social and material contexts in which professionals interact with LLMs. Through spontaneous and deliberately imperfect sketches, participants capture their intuitive and metaphorical understanding of LLMs.
Exercise 2 - Harvesting Tasks
Participants account for the tasks they perform in their work and how LLMs could assist them.

This exercise helps participants reflect on their existing work, revealing overlooked or underappreciated tasks.
They also explore what other work they could do with the assistance of an LLM, generating material for future exercises.
Exercise 3 - Taking Stock
Participants review their ChatGPT history to identify usage patterns and what stands out.

This exercise prompts participants to critically assess their LLM interactions through self-evaluation and a structured review of their conversation history.
It highlights gaps between perception and actual use to further their understanding of their LLM usage rather than relying on habitual talking points or anecdotes.
Exercise 4 - Memorable Conversations
Participants identify what made some conversations with ChatGPT remarkable.

Participants analyze past LLM interactions that stood out due to emotional impact, moral hesitation, or significant outcomes.
They rate the model's performance and explore why it performed as it did, fostering awareness about LLM capabilities and professional expectations.
Exercise 5 - Subtracting the Machine
Participants describe memorable interactions with ChatGPT without using terms like 'LLM' or 'ChatGPT'.

This thought experiment creates artificial constraints on how participants talk about their use of LLMs.
Because they cannot rely on ready-made categories (e.g., 'ChatGPT', 'machine', or 'assistant'), participants need to reconsider their interactions with the models, playing with different metaphors and analogies drawn from their social and professional environments.
Ecologies of LLM Practices
How can we reframe the role of LLMs in ordinary work practices?
The booming rise of large language models (LLMs) such as ChatGPT has sparked a rush to produce discourse about these technologies. The quick crystallisation of a shared outlook around a few key themes has narrowed the scope of potential interrogations. Public and scientific debates focus on technical issues: algorithmic bias, confabulation, and intellectual property violations. However, the problems and consequences associated with their actual use – for both their users and their professional contexts – remain largely unexplored. This asymmetry fuels a mechanical view of technological development and its effects, as if the technical analysis of these systems were enough to predict their social impact. Moreover, these discourses present AI as a monolithic and disruptive entity, dismissing the possibility that it may be aligned with existing practices and that its effects may vary depending on situations encountered in one's job. There is thus an urgent need to move beyond predictions about the future of work, to account for the professional contexts in which LLMs are used, and to identify current issues – not prospective ones. How do AI's well-known problems (bias, confabulation, etc.) manifest in established practices? What new, unexpected problems are surfacing? How do LLMs shape individual work practices? And in turn, how do professional environments shape LLMs and their use?

Benchmarking
How do we assess the value of an LLM?
In this block, participants are guided through selecting an LLM that best suits their professional needs. They design personal tests comprising specific tasks and evaluate the performance of different models.
The goal is to choose a model that aligns with their practical and ethical requirements.

Exercise 6 - Design your AI Trial
Participants design a trial to test the usefulness of an LLM, choosing four tasks that are essential or enjoyable parts of their work.

This exercise guides participants through a selection process, drawing from their current work practices and the potential implementation of new tasks.
In contrast to standardized benchmarks, which are tailor-made by engineers for LLMs, participants design a trial that revolves around their professional experience.
This personalized benchmark aims to assess whether the models can provide practical value that actually matters in a specific professional situation.
Exercise 7 - Preparing for the Trial
Participants write detailed instructions for their tasks and choose four LLMs they wish to test.

By formulating detailed instructions, participants reflect on how they can effectively guide an LLM toward accomplishing a simple or complex task. They are led to reflect on the weight of their own prompt on the final result.
By selecting a human or a specialized model, participants explore different avenues of comparison - machine versus machine or human versus machine.
Exercise 8 - Gathering Evidence
Participants ask an acquaintance to collect answers from LLMs and anonymize results to avoid bias.

In this exercise, participants enlist the help of a fellow co-inquirer, a good friend, or a colleague.
In addition to anonymizing results and ensuring fairness in the upcoming trial, this exercise allows participants to concretely experience the collaborative nature of LLM performance evaluation.
Exercise 9 - Judgment Day
Participants assess the blind results of their AI trial: they rank them, explain on what ground they assessed each performance, and reflect on the trial process.

Participants rank anonymized LLM responses for each task, determine the best-performing model, and critically review the trial's fairness and relevance.
This evaluation encourages participants to reflect on what matters in assessing the situated value of LLMs.
Objective
How do professionals evaluate, adapt to, and perceive LLMs in their work?
To answer these questions, the Ecologies of LLM Practices (EL2MP) project creates research areas dedicated to workers for them to document and reflect on their use of LLMs. Our investigation aims to highlight the "savoir-faire", expertise, and values of workers rather than those of AI designers or economic decision-makers. The project aims to scrupulously examine how LLMs fit into various professional practices. EL2MP will investigate how users relate to LLMs in terms of:
Evaluation: How do professionals assess the value LLMs add or remove?
Effort: What new kinds of work do LLMs require from their users?
Perception: How do workers evaluate and perceive LLMs over time as they continue working with them?
Prompting
To what extent can we influence the quality of an LLM's output?
In this block, participants explore how to effectively communicate with LLMs through prompt engineering. They experiment with different prompt styles and techniques to see how they influence an LLM's outputs, aiming to better align the model's responses with their professional needs and expectations.

Exercise 10 - The Art of the Prompt
Participants read about prompting techniques, attempting to put them into practice and share their insights with the group.

Participants explore a specific prompting technique by practicing it throughout the week, and summarizing their findings in a concise presentation. The goal is to develop a nuanced understanding of how prompt design influences LLM responses.
Knowledge acquired about a prompting technique is shared among all participants through a short presentation, based on observations they kept track of in a personal diary.
Exercise 11 - Tracking Shifts
Participants look back on their LLM practices since the experiment began, searching for shifts and continuities.

Participants document how their use of LLMs has changed since the beginning of the experiment. They write two short essays—one on how their practices have evolved and another on what has remained stable—using concrete examples from their experience.
Through a structured discussion game, participants also analyze their shifting perspectives on LLMs. The goal is to engage in collective reflection in order to challenge assumptions and reinforce insights gained through the experiment.
Methodology
A necessary project in today's research landscape on LLMs
To carry out the project, we developed an experimental research protocol based on the active involvement of participants. The fruit of a collaboration between sociologists, science and technology researchers (STS), and designers, this protocol aims to create:
Room for hesitation: Through a series of exercises, the protocol provides participants with various means of documenting and reflecting on their use of LLMs. We aim to establish a framework where doubt and hesitation are not only accepted but encouraged. Some exercises introduce deliberate pauses in professional routines, causing participants to take a step back from their own practices: during these pauses, judgment is suspended, giving users enough room to question their instinctive habits and feel unsure about what they once thought was certain. Other exercises aim to intensify the use of LLMs to shed light on what would otherwise remain too subtle to be perceived.
An ecological archive of practices: The digital traces from LLM use serve as the starting point for the exercises we designed. They are analysed, contextualised, and discussed individually and collectively. Through this process, participants progressively build a multimodal archive (audio, photos, videos, drawings, and logbooks) that tangibly reflects their LLMs experience and how they are incorporated into various professional norms and material configurations.
A workbook (vademecum): The workbook collects all the exercises and their instructions, organized into thematic blocks. Designed as a modular object, where pages can be added or removed as needed, it accompanies each participant throughout the protocol. The vademecum serves as both the material support for the protocol and the project's means of dissemination, as it can be reproduced and adapted in various academic and professional contexts.
Excelling
How closely can an LLM approach human excellence?
In this block, participants use their chosen LLM to produce the highest quality work possible, attempting to recreate a masterpiece from their field. The goal is to push the model's capabilities to the fullest, testing its ability to reach the gold standard in a specialized field.

Exercise 12 - Choosing Your exemplary Work
Participants identify and reflect on written texts that set a benchmark in their field—models worth emulating.

An exemplary work is not necessarily a prestigious publication but also modest, everyday writings that embody clarity, precision, or impact within a professional context. By selecting both renowned and less conspicuous examples, the goal is to sharpen awareness of what good writing looks like across different formats and purposes.
Exercise 13 - The Imitation Game
Participants guide an LLM towards reproducing an exemplary text from their professional field, aiming to create an exact copy.

Participants attempt to recreate a high-quality text using an LLM without providing direct access to the original. This experiment tests the LLM's ability to replicate style, tone, and meaning while challenging participants to refine their prompting strategies.
Through 90-minute work sessions, screen recordings, and a logbook, participants document their process and assess the model's capacity to (re)produce a text it does not have access to.
Exercise 14 - Setting Up the Example
Participants discuss the place of their chosen work within their professional ecology and explain why it's exemplary.

This exercise contextualizes the chosen exemplary work by examining its professional significance. A radar graph helps assess factors like frequency, expertise required, and error tolerance, while a structured reflection highlights what makes the work exemplary and worth emulating.
Exercise 15 - Anatomy of an Exemplary Work
Participants break down their exemplary work into its main components and assess which elements are accessible to an LLM.

Participants analyze the underlying structure of their chosen text, mapping its key influences, professional constraints, and dependencies.
A layered dependency graph helps distinguish which elements are accessible to an LLM and which remain beyond its reach, reinforcing an understanding of AI's limitations.
Exercise 16 - Obstacles, Dead Ends, Highways
Participants examine key moments in navigating the LLM—obstacles, dead ends, and highways.

By identifying challenges that can be overcome through iteration or adapting a prompt, situations where the LLM fails to generate meaningful progress despite repeated attempts, and effortless response generation, participants discover patterns in their experiences and develop a clearer sense of when to persist, pivot, or abandon a strategy.
Exercise 17 - Charting Your Path
Participants sketch three evolving, hand-drawn graphs depicting their learning journey.

By mapping progress horizontally and obstacles vertically, the drawing becomes a living diagram of how one navigates challenges, setbacks, and breakthroughs while learning a new skill with the help of an LLM. It encourages an intuitive, embodied reflection on learning —where success isn’t linear, and detours or derailments become part of the story.
Contact
Our Team
Donato Ricci: Principal Investigator, Designer
Contact: donato.ricci@sciencespo.fr
Gabriel Alcaras: Postdoctoral researcher, Sociologist
Contact: gabriel.alcaras@sciencespo.fr
Tommaso Prinetti: Research Assistant, Designer
Contact: tommaso.prinetti@sciencespo.fr
Zoé de Vries: Research Assistant, Linguist
Contact: zoe.devries@sciencespo.fr
Distilling
What story emerges when we look back on our evolving relationship with LLMs?
In this final block, participants circle back to the essential aspects of their use of LLMs. Delving into previous exercises, they uncover key features that have remained stable or which have evolved during the course of the experiment, thus producing a detailed overview of the integration of LLMs within their workflow.

Exercise 18 - Choosing Your exemplary Work
Participants synthesize their own perspective on the entire experiment into a cohesive narrative.

Rather than summarizing past exercises, this exercise encourages the creation of a personal booklet that combines selected pages from the vademecum with additional notes, sketches, and digital traces. This curated archive serves as both a tangible memory and a storytelling device —capturing key moments, doubts, and insights that have shaped the participant’s evolving relationship with LLMs.
Co-Inquirers
We would like to thank all co-inquirers who took part in our protocol. Without their participation, our project could not have been developed.
Clara Demarty-Coadic
François Lambert
Josephine Preißler
Léa Stephan
Lukas Brand
Mathilde Blanchon
Thérèse d'Orléans
Yajing Hu
The booming rise of large language models (LLMs) such as ChatGPT has sparked a rush to produce discourse about these technologies. The quick crystallisation of a shared outlook around a few key themes has narrowed the scope of potential interrogations. Public and scientific debates focus on technical issues: algorithmic bias, confabulation, and intellectual property violations. However, the problems and consequences associated with their actual use – for both their users and their professional contexts – remain largely unexplored. This asymmetry fuels a mechanical view of technological development and its effects, as if the technical analysis of these systems were enough to predict their social impact. Moreover, these discourses present AI as a monolithic and disruptive entity, dismissing the possibility that it may be aligned with existing practices and that its effects may vary depending on situations encountered in one's job. There is thus an urgent need to move beyond predictions about the future of work, to account for the professional contexts in which LLMs are used, and to identify current issues – not prospective ones. How do AI's well-known problems (bias, confabulation, etc.) manifest in established practices? What new, unexpected problems are surfacing? How do LLMs shape individual work practices? And in turn, how do professional environments shape LLMs and their use?
Try this website on a 💻 device.